



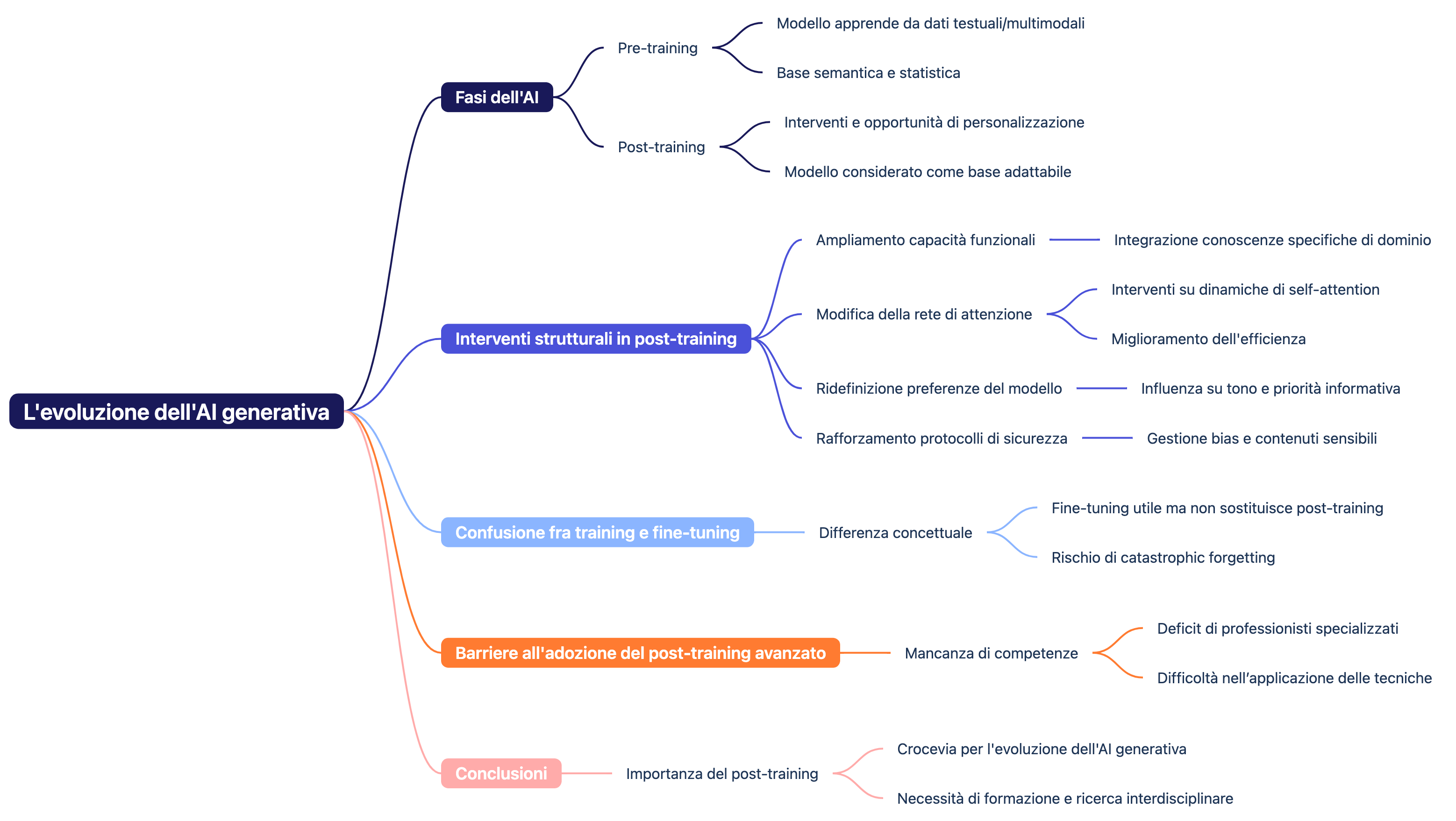
Nel dibattito scientifico e industriale odierno, l’attenzione rivolta ai modelli di intelligenza artificiale generativa tende a concentrarsi quasi esclusivamente sulla fase di pre-training, ovvero il momento in cui il modello apprende da enormi corpus di dati testuali o multimodali in maniera auto-supervisionata. Questa fase costituisce senza dubbio il fondamento della struttura semantica e statistica del modello, ma non rappresenta l’unico punto nevralgico dell’innovazione odierna.
Negli ultimi dodici mesi, la ricerca nel campo dell’AI generativa ha orientato il proprio focus verso la fase di post-training, una fase che offre nuove e decisive opportunità di intervento, personalizzazione e raffinamento funzionale. In tale contesto, il modello pre-addestrato non viene più considerato come una struttura chiusa, bensì come una base adattabile e dinamica, su cui è possibile agire mediante tecniche mirate che ne alterano profondamente il comportamento e le capacità.
Interventi strutturali in post-training
In fase di post-training, è possibile:
- Ampliarne le capacità funzionali, integrando conoscenze specifiche di dominio (es. lessico tecnico, stile settoriale, strutture argomentative peculiari).
- Modificare la rete di attenzione, intervenendo sulle dinamiche interne dei meccanismi di self-attention che governano l’allocazione dell’attenzione tra i token. Ciò permette non solo un miglioramento dell’efficienza, ma anche una diversa interpretazione del contesto linguistico (Cocce Srl).
- Ridefinire le preferenze del modello (model preferences), influenzandone il tono, l’esposizione e la priorità informativa nei processi inferenziali (anpili74.medium.com).
- Rafforzare i protocolli di sicurezza e controllo (safety e guardrails), inclusa la gestione dei bias e dei contenuti sensibili, tramite l’applicazione di tecniche derivate dalla teoria dei sistemi complessi e dalla sicurezza informatica (ICT Security Magazine).
Training, Fine-Tuning e il malinteso diffuso
Nel contesto applicativo, specialmente in settori quali l’editoria digitale e la produzione di contenuti culturali, si riscontra spesso una confusione concettuale tra le diverse fasi di addestramento. In particolare, si tende a sovrapporre il concetto di training con quello di fine-tuning. Quest’ultimo, sebbene utile per specializzare un modello su un sottoinsieme di dati o compiti, non sostituisce le metodologie sistemiche del post-training, e può addirittura risultare controproducente se condotto in modo non controllato (TabataTech).
La pratica del fine-tuning, infatti, espone il modello al rischio di catastrophic forgetting, ovvero la perdita di informazioni acquisite durante il pre-training. Questo fenomeno compromette la generalizzazione del modello e può causare una regressione qualitativa nelle risposte, oltre che problemi etici e di sicurezza nei deployment produttivi (AI Joy Academy).
La carenza di competenze nel post-training avanzato
Una delle principali barriere all’adozione delle pratiche di post-training avanzato è la mancanza di risorse umane altamente specializzate. Il mercato dell’AI soffre di un deficit cronico di professionisti con competenze trasversali in machine learning, linguistica computazionale, sicurezza informatica e design dei comportamenti generativi. Questo rende difficile per molte aziende distinguere le varie tecniche disponibili e applicarle in modo efficace e sostenibile (Fastweb).
Conclusioni
La fase di post-training si configura oggi come il vero crocevia per l’evoluzione dell’AI generativa. Essa permette interventi sofisticati e mirati, capaci di trasformare un modello generalista in uno strumento altamente specifico e performante. Per coglierne appieno le potenzialità, è però necessario abbandonare una visione semplicistica basata esclusivamente su training e fine-tuning, e investire in formazione, ricerca interdisciplinare e sviluppo di nuovi paradigmi operativi.
Riferimenti:
- AI Joy Academy – Pre-training vs Fine-tuning
- ICT Security Magazine – Generative AI e rischi
- TabataTech – Differenze tra Fine-Tuning e RAG
- Fastweb – Formazione sull’AI generativa
- Cocce Srl – L’importanza dell’attenzione
- Andrea Pili su Medium – Training, Fine-Tuning o Inference?
{kind=link}
🎙️ VERSIONE SCRIPT PER VIDEO/PODCAST (durata stimata: 2-3 minuti)
 Giulia
Giulia
Oggi, miei cari ascoltatori, parleremo di un argomento che sta guadagnando sempre più attenzione: il post-training nell’intelligenza artificiale, e come questo approccio può trasformare i nostri modelli pre-addestrati in strumenti potenti e personalizzati. La fase di pre-training, dove i modelli apprendono da volumi massicci di dati, è solo il primo passo. Ma voilà, qui arriva il post-training! Avete presente un buon vino? Se lo lasciate invecchiare nella bottiglia, diventa qualcosa di veramente speciale. Così, il post-training ci permette di rifinire una rete già esistente e migliorarne le capacità funzionali.
 Luca
Luca
Hmm, aspetta un attimo! Quindi tu dici che c’è qualcosa dopo il pre-training? È come se stessi parlando di un’ulteriore fase di apprendimento? Oh wow! È un po’ come quando stai imparando a suonare uno strumento musicale, giusto? [laughs] All’inizio è tutto confuso e pieno di errori, ma con la pratica e magari con l’insegnante giusto, diventi un virtuoso! Ma se un insegnante finisce per insegnarti solo una tecnica ignorando alcune abilità importanti? È qui che entra in gioco il fine-tuning di cui hai parlato, vero?
Giulia
Esattamente, brillante! Il fine-tuning è come adattare il tuo metodo di studio a seconda dell’argomento. Ma attenzione, potremmo compromettere la capacità del modello di apprendere informazioni cruciali. Immagina se un pianista si concentrasse solo su scale e arpeggi e dimenticasse come suonare una melodia. Questo è il rischio del fine-tuning se non gestito correttamente. Ecco perché il post-training è così importante: migliora senza sacrificare le abilità fondamentali.
Luca
Quindi, fammi capire meglio… Se ho un modello di AI che ha appreso bene durante la fase di pre-training, ma poi mi concentro solo sul fine-tuning, rischio di rovinare tutto? [sigh] Come un chef che si concentra solo sulla decorazione del piatto senza preoccuparsi di ingredienti freschi e di qualità! È così?
Giulia
Perfettamente! Questa metafora del chef è un’ottima analogia! In effetti, la mancanza di esperti nel post-training avanzato può essere una seria battuta d’arresto. Dobbiamo investire in formazione e ricerca interdisciplinare per sbloccare il potenziale dell’AI generativa. Pensate a come i migliori cuochi del mondo collaborano con scienziati e agronomi. Così, possiamo fare in modo che l’AI non solo funzioni bene, ma si evolva e migliori nel tempo.
Luca
Wow, i fuochi d’artificio! [laughs] Quindi, in altre parole, l’AI deve essere come un vero e proprio piatto gourmet. Ma, umm, ci sono tecniche specifiche che i ricercatori stanno già usando per fare il post-training in modo efficace? Dato che stiamo parlando di rischio di perdita di informazioni, possiamo paragonarlo a una ricetta segreta che si perde nel processo!
Giulia
Hai colto nel segno! Per un post-training efficace, dobbiamo adottare un approccio sistemico. Dobbiamo essere strategici e usare tecniche come l’adattamento della rete di attenzione. È come organizzare una brigata in un ristorante: ogni membro ha un compito e, insieme, creano un’opera d’arte culinaria. Un lavoro da esperti, non possiamo permetterci di improvvisare!
Luca
Giustissimo! Ah, immagino di avere un ristorante di successo e poi un giorno, qualcuno con una ricetta strana entra e stravolge tutto. [sigh] È un po’ spaventoso pensare a quanto possa essere delicato! Ultima cosa: come si fa a trovare il giusto equilibrio tra queste modifiche e il mantenimento dell’autenticità del modello? Hmmm! Questo mi fa pensare a certi ristoranti che provano mille cose nuove e poi perdono il loro carattere unico!
Giulia
Ecco, la vera sfida! Mantenere l’autenticità significa avere un chiaro indirizzo su dove vogliamo portare il nostro modello. Se miriamo a esplorare nuove frontiere dell’AI generativa, allora il bilanciamento fra innovazione e rispetto del patrimonio ‘culturale’ del modello diventa cruciale. È come prendere una tradizione culinaria e darle un martellante colpo di innovazione per creare… la cucina contemporanea! Non è semplice, ma con il giusto metodo, possiamo arrivarci!
Luca
Wow! Non vedo l’ora di provare a pensare a questo come a un’avventura gastronomica nel mondo dell’intelligenza artificiale! [laughs] Grazie per queste intuizioni! Il mondo dell’AI sembra proprio un piatto ricco e variegato, e voglio assaporarlo tutto.
Giulia
Esattamente! E per assaporarlo tutto, dobbiamo essere curati nelle nostre scelte di post-training, un po’ come un sommelier che sceglie il vino perfetto da accompagnare al pasto. Ogni scelta deve riflettere l’armonia tra sapore e tecnica.
Luca
Hmm, proprio così! E spero di non rovinare mai il ‘pasto’ dell’intelligenza artificiale, [sigh] perché buoni ingredienti e metodo sono essenziali per un grande risultato! Da dove iniziamo, quindi?
Ascolta sul tuo telefono